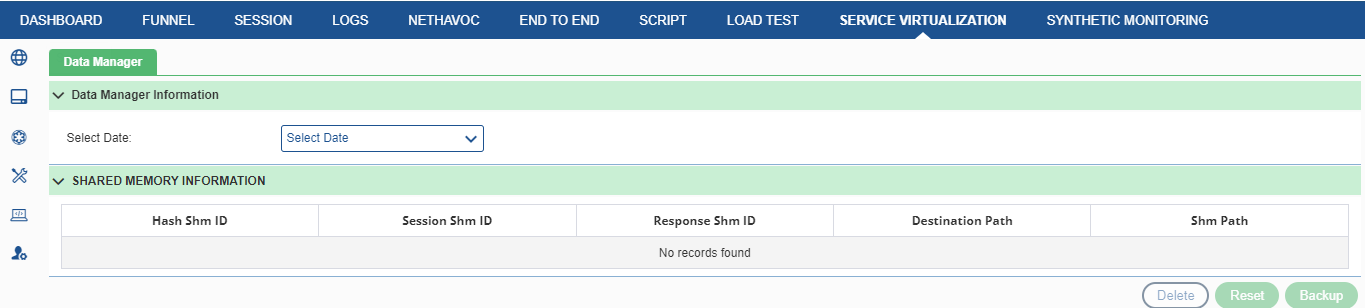
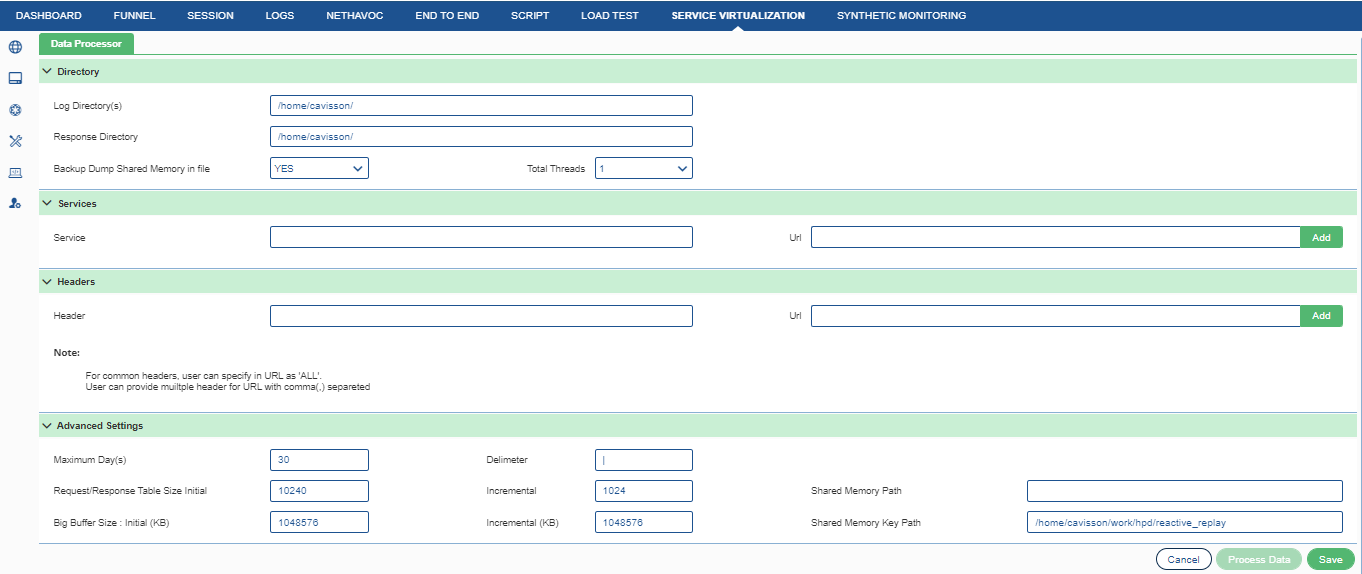


To delete an already added header, click the delete button corresponding to the header. The header gets deleted from the list.
For common headers, user can specify in URL as ‘ALL’. User can provide multiple header for URL with comma(,) separated |
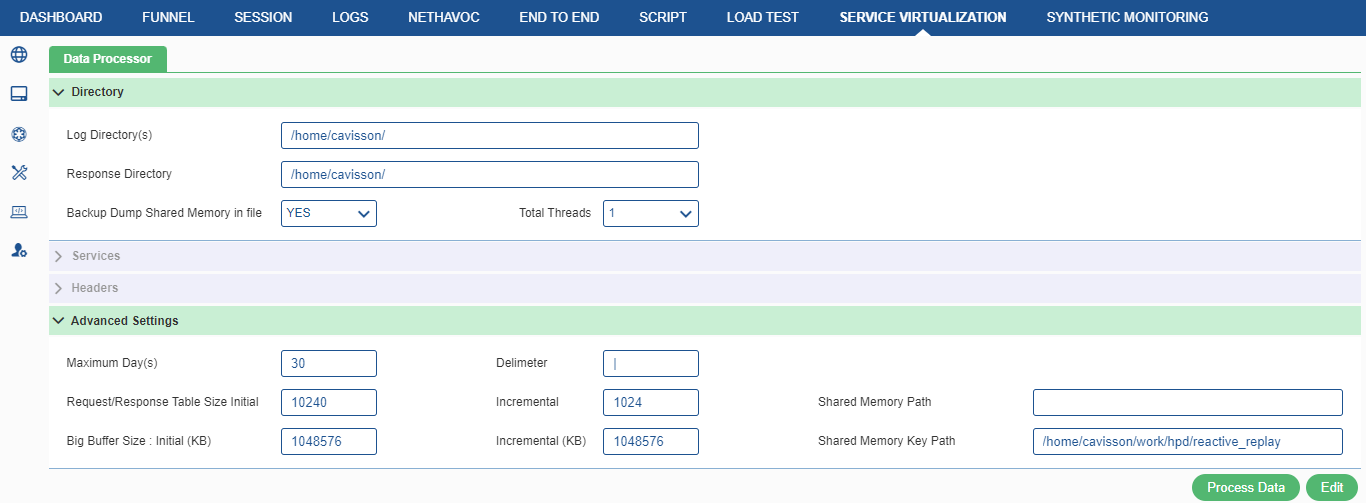
Advanced Settings
Here, in this section, user can configure some advance settings for data processor. To perform the advance settings, go to Advanced Settings, sub-section: